
Datawrapper で乱雑なデータに悩まされるのはもうやめましょう
データ分析ワークフローにおける最大のボトルネックは、多くの場合、データ クリーニングのステップです。最先端の視覚化ツールを使用することはできますが、データが汚れていると、ダッシュボードが壊れ、洞察が誤解を招くことになります。
Datawrapper のユーザーにとって、データ クリーニングの苦労は非常に現実的です。 アップロード ステップでの手動スプレッドシート編集であっても、乱雑なファイルによる一般的な悩みであっても、ビジュアライゼーションの可能性を最大限に引き出す鍵は、データが Datawrapper に到達する 前にクリーンアップすることです。
最も一般的なデータの問題: 日付列
データ アナリストにとって日付列は最も一般的な悩みの種です。データセットを Datawrapper にインポートすると、次の理由で時系列グラフが突然壊れます。 ※一部の日付は「DD/MM/YYYY」(欧文形式)となっております。 ※その他は「MM-DD-YYYY」(米国式)となります。 ※「2024年1月12日」のような単なる文字列もございます。
Datawrapper 内でこれを修正しようとするのは悪夢です。結局、複雑な解析関数を作成したり、厳格な数式を作成したり、Excel でセルを手動で編集したりすることになります。間違いが発生しやすく、面倒です。
私たちの理念:「すべてを受け入れ、一つをアウトプットする」
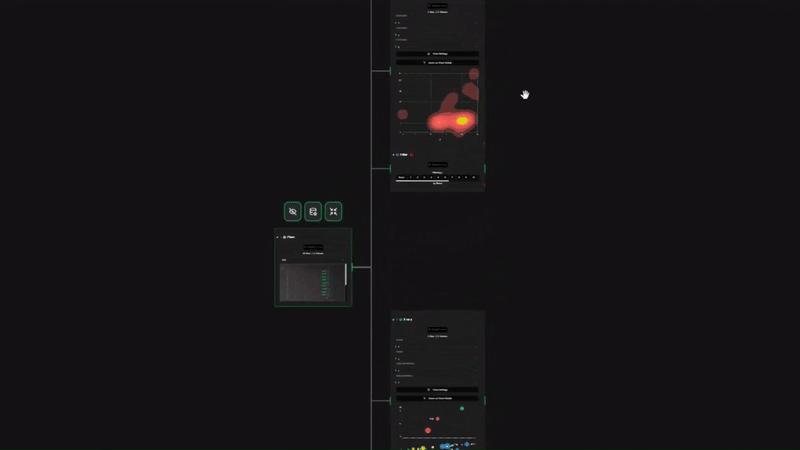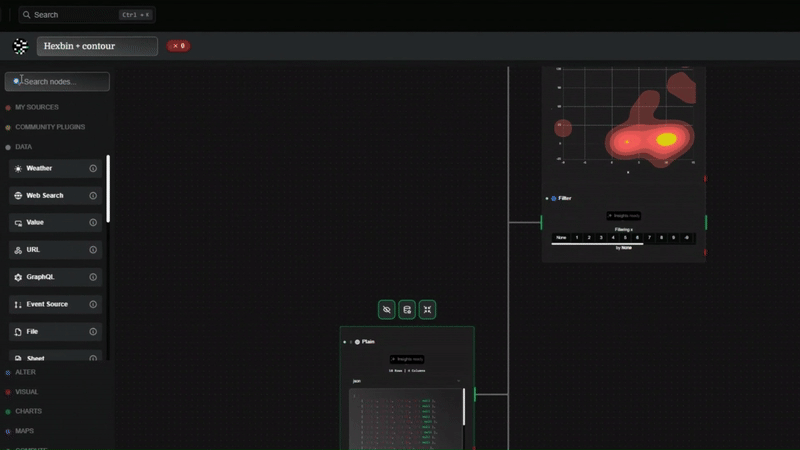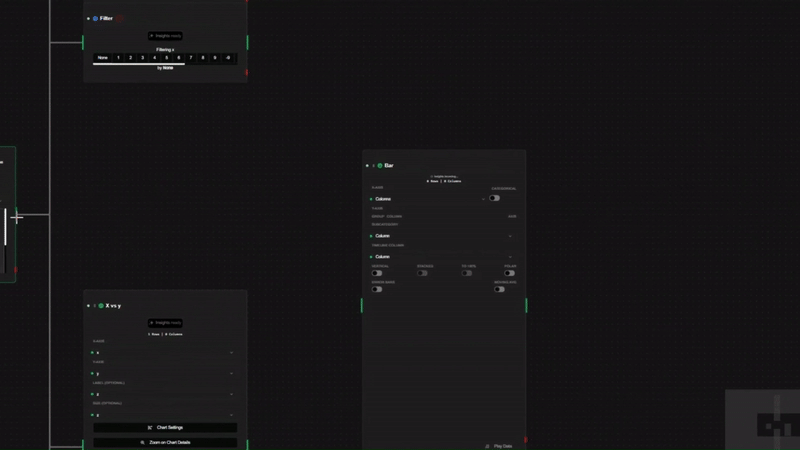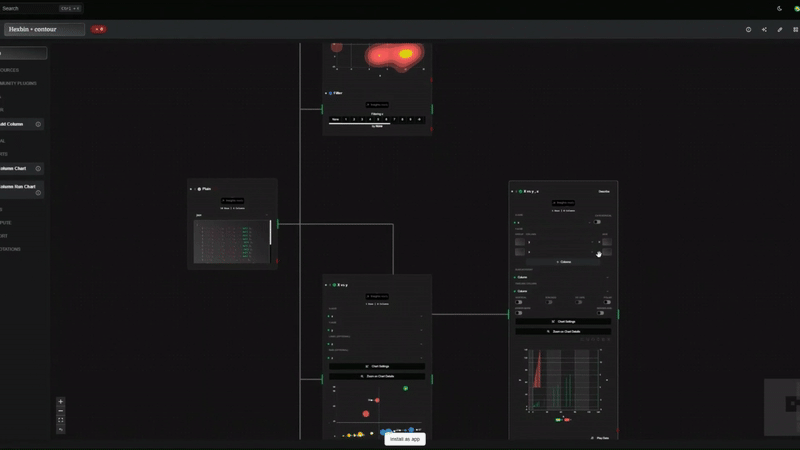
データ クリーニング、特にタイムスタンプに関して、Datatripes は根本的に異なるアプローチを採用しています。 当社は「すべてを受け入れ、出力は 1 つ」を信じています。つまり、日付形式を定義するためのコードの作成をユーザーに求める代わりに、Datatripes は 混合形式を自動的に受け入れるスマートな取り込みエンジンを使用します。
- まず、生の CSV をドロップします。データストライプは、5 つの異なる形式が混在している場合でも、Date 列を検出します。
- 次に、システムはすべてを単一の世界標準 (ISO 8601) に自動的に変換します。
- 最後に、タイムライン分布がすぐに表示されます。外れ値 (2099 年の日付など) がある場合は、それらを視覚的に見つけて、クリックするだけで除外できます。 日付が「どのように」書かれるかについて心配する必要はありません。出力されるのは、クリーンでソート可能なタイムスタンプであることがわかります。
日付を超えたビジュアルデータのクリーニング
データストライプの威力は日付のクリーニングだけではありません。 Datawrapper にデータを送信する前にビジュアル ノード フローを使用すると、次のことが可能になります。
- ヒストグラムを使用して視覚的に外れ値をフィルタリングします。
- カテゴリをグループ化 (例: 「USA」、「U.S.」、および「US」を「United States」に変換) シンプルなインターフェースを介して。
- SQL を記述せずに ID に基づいて行の重複を排除します**。
今度はあなたの番です
数分で視覚的にデータのクリーニングを開始し、Datawrapper で使用できるようにエクスポートします。 Data Stripes を無料で試してください して、初めてデータを明確に確認してください。