
Datawrapper で視覚化する前にデータをクリーンアップする方法
データ分析の黄金律はシンプルですが残酷です: 「ガベージイン、ガベージアウト」
Datawrapper を使用している場合は、その視覚化機能が気に入っているでしょうが、そのためのデータを準備するのが面倒なことはおそらく嫌いでしょう。 手動のスプレッドシート編集に取り組んでいる場合でも、アップロード ステップでダッシュボードを壊す乱雑なファイルにうんざりしている場合でも、インポートの前*にデータをクリーンアップすることが、ストレスのないワークフローの秘訣です。
特定の悪夢: タイムスタンプと日付
データ アナリストにとって最大の敵は日付列です。 ご存知のとおり、このドリルは、Datawrapper にデータセットをインポートすると、次の理由で突然時系列グラフが壊れてしまいます。 ※一部の日付は「DD/MM/YYYY」(欧文形式)となっております。 ※その他は「MM-DD-YYYY」(米国式)となります。 ※「2024年1月12日」のような単なる文字列もございます。
Datawrapper 内でこれを修正するには、通常、複雑な解析関数を作成するか、厳格な数式を作成するか、Excel でセルを手動で編集する必要があります。間違いが発生しやすく、退屈です。
データストライプの哲学: 「すべてを受け入れ、1 つを出力する」
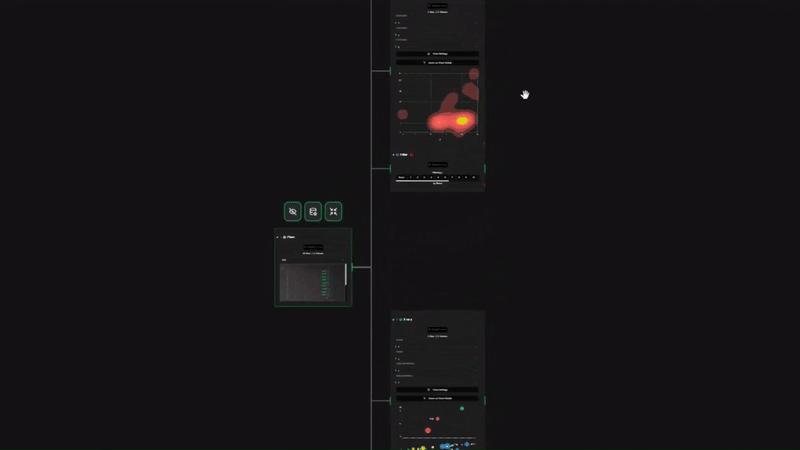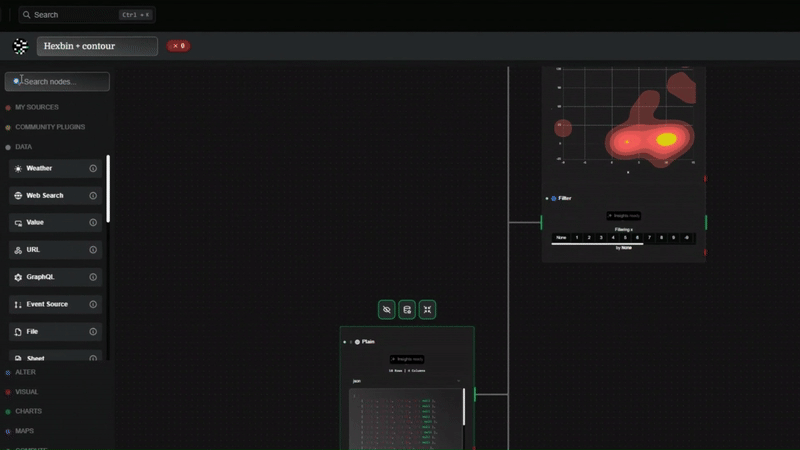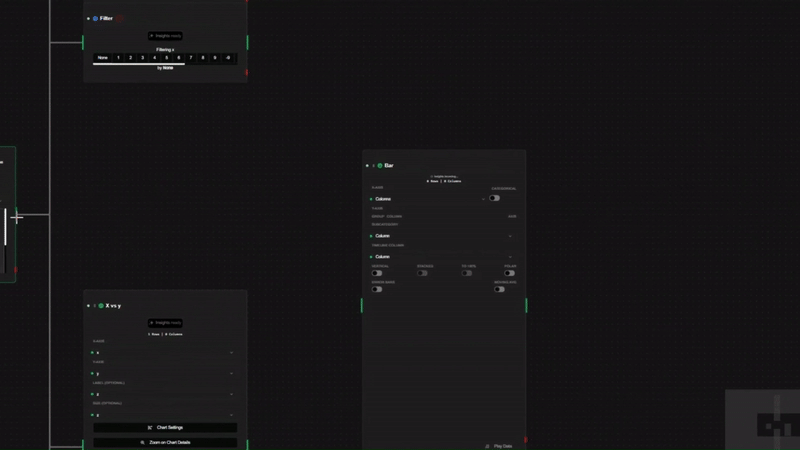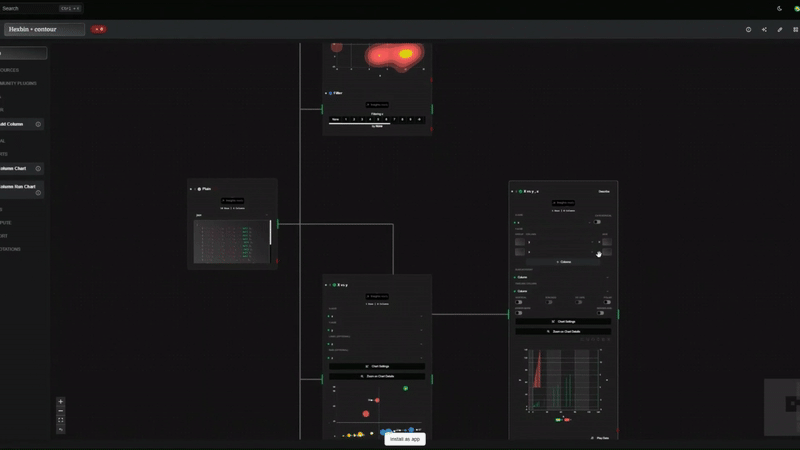
Datatrips は、特にタイムスタンプに関して、データ クリーニングに対して根本的に異なるアプローチを採用しています。
データストライプは、日付形式を定義するためのコードを記述する代わりに、混合形式を自動的に受け入れるスマートな取り込みエンジンを使用します。
- 取り込み: 生の CSV をドロップします。データストライプは、5 つの異なる形式が混在している場合でも、Date 列を検出します。
- 標準化: システムはすべてを単一の普遍的な標準 (ISO 8601) に自動的に変換します。
- 視覚チェック: タイムラインの分布がすぐに表示されます。外れ値 (2099 年の日付など) がある場合は、それらを視覚的に見つけて、クリックするだけで除外できます。 日付が「どのように」書かれるかについて心配する必要はありません。出力されるのは、クリーンでソート可能なタイムスタンプであることがわかります。
日付を超えて: ビジュアル パイプライン
デートだけの話ではありません。 Datawrapper にデータを送信する前にビジュアル ノード フローを使用すると、次のことが可能になります。
- SQL を記述せずに ID に基づいて行の重複を排除します**。
- カテゴリをグループ化 (例: 「USA」、「U.S.」、および「US」を「United States」に変換) シンプルなインターフェースを介して。
- ヒストグラムを使用して視覚的に外れ値をフィルタリングします。
Datawrapper で実行してみてはいかがでしょうか?
Datawrapper は、データを 視覚化 および 分析 するために設計されており、必ずしもダーティ ファイルをスクラブするために設計されているわけではありません。 手動のスプレッドシート編集に大量のクリーニング ロジックの負荷がかかると、ダッシュボードの速度が遅くなり、メンテナンスが困難になります。
Datatripes を軽量の「前処理」レイヤーとして使用することで、元のデータセットを Datawrapper に引き渡します。
- ダッシュボードの読み込みが速くなります。
- 数式がよりシンプルになります。
- 日付形式のデバッグをやめて、洞察を見つけ始めます。
試してみてください
面倒な CSV や複雑なスクリプトと格闘するのはやめましょう。データを数分で視覚的にクリーンアップし、Datawrapper で使用できるようにエクスポートします。
データストライプを無料で試してください すると、初めてデータが明確に表示されます。